plot of chunk unnamed-chunk-10
There are two exercises for Homework 2. The first is about bootstrapping, and the second is about classification. Specifically:
The first exercise is a replication exercise. Your task is as follows: when you find the R scripts missing for the numeric/figure outputs, provide the R scripts yourself. Your output should match my outputs exactly if you have followed the procedures described in the exercise.
The second exercise is essentially a mini-report of classification analysis, which leaves you lots of room for creativity.
Bootstrapping is a resampling method commonly used to calculate the standard error (and confidence intervals) of an estimator. This assignment uses an artifical example of “weighing panda Yaya” to illustrate the use of bootstrapping.
Set the random seed:
set.seed(2048)The panda keeper wants to measure the weight of panda Yaya. She lures Yaya onto the scale multiple times, but because Yaya keeps moving on the scale, each measurement may have a large error.
Assume the keeper weighs Yaya ten times, and the recorded weights are:
k_weights <- c(93, 77, 62, 78, 75, 85, 66, 83, 91, 72)A simple way to reduce noise is to take the mean:
#> 78.2The sample mean we obtain, 78.2, is just “one” statistic. Without additional assumptions to specify the “model” of panda Yaya’s weight, we cannot perform statistical inference on this result nor assess its accuracy.
We use the sample() function for resampling. Unlike
cross‑validation, bootstrapping uses sampling with replacement, so we
set replace=TRUE:
sample(k_weights, size=10, replace=TRUE)
#> [1] 66 93 83 91 62 91 62 62 72 75We perform K = 100 resamplings:
K = 100
panda_boots <- replicate(K, sample(k_weights, size=10, replace=TRUE))Check that the resulting resampled data panda_boots is a
matrix with 10 rows and 100 columns:
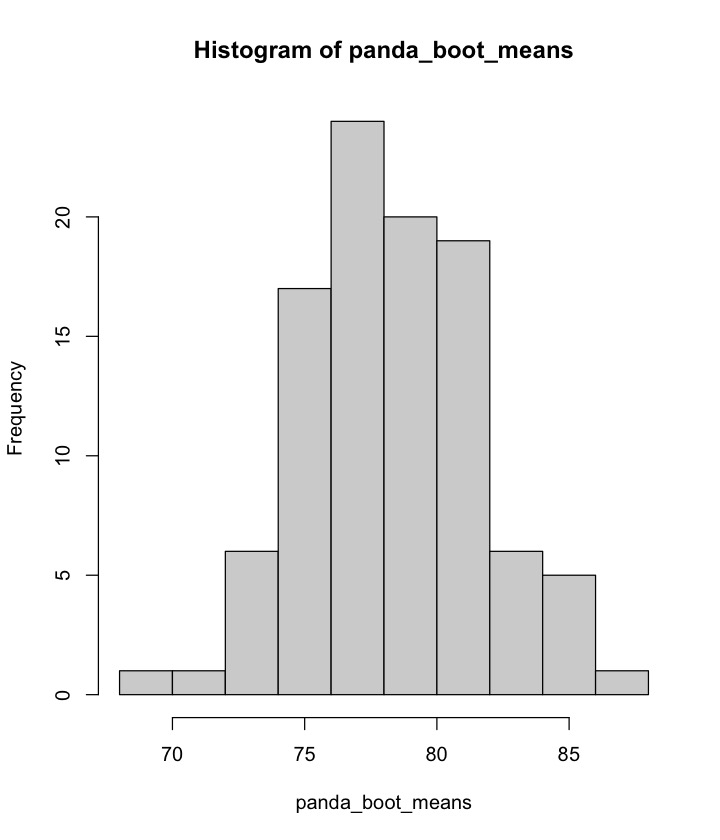
#> [1] 10 100We compute the mean of each column, obtaining a vector of length 100:
panda_boot_means <- apply(panda_boots, 2, mean)
length(panda_boot_means)
#> [1] 100panda_boot_means contains more information than
mean(k_weights). Intuitively, panda_boot_means
can be seen as 100 realizations of the mean statistic.
The (sample) variance of panda_boot_means can be used as
an estimate of the standard error of the mean statistic (the bootstrap
standard error).
#> [1] 3.278438plot of chunk unnamed-chunk-10
In the analysis above, we performed K = 100 resamplings.
With modern computers, we can perform K = 1000 or
K = 10000 resamplings to obtain a more accurate estimate of
the standard error. Moreover, a larger K helps us construct
more accurate confidence intervals for the mean statistic.
In this simple example, by the Central Limit Theorem, when K is
large, panda_boot_means should be approximately normally
distributed. We can directly construct a 95% confidence interval using
the bootstrap standard error:
qnorm(0.025)[1] -1.959964K = 10000
panda_boots <- replicate(K, sample(k_weights, size=10, replace=TRUE))
panda_boot_means <- apply(panda_boots, 2, mean)panda_boot_means:
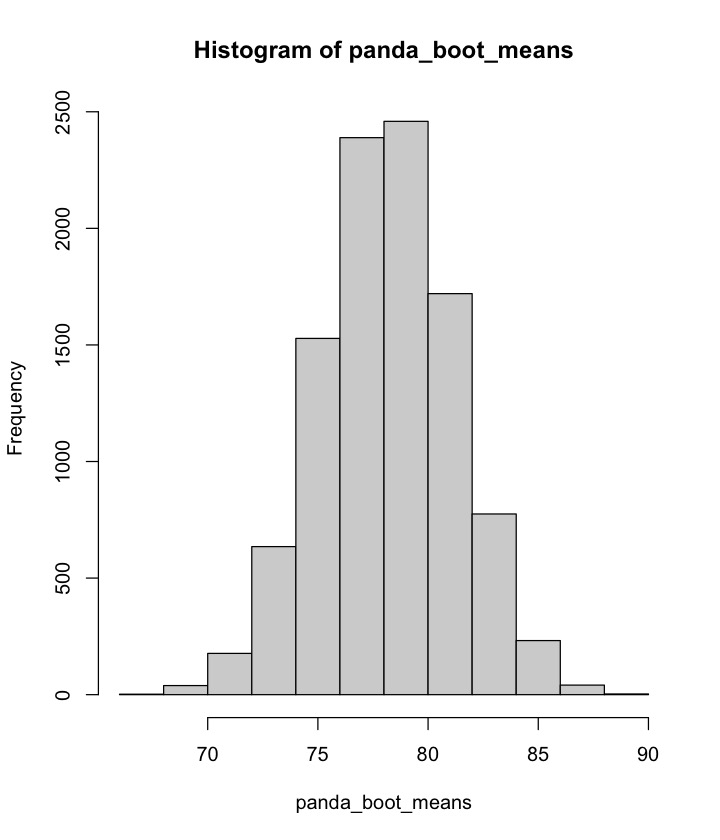
plot of chunk unnamed-chunk-12
Below is the confidence interval. The formula is
,
where the value 1.96 is obtained from the R expression
qnorm(0.025).
#> [1] 72.22867 84.17133This exercise illustrates the bootstrap method with a simple example.
We have used the sample() function for resampling.
You should first install the R package ISLR2 if you have
not done it yet:
install.packages("ISLR2")This is the accompanying R package for our textbook, Intro to Statistical Learning. This package provides many useful data sets:
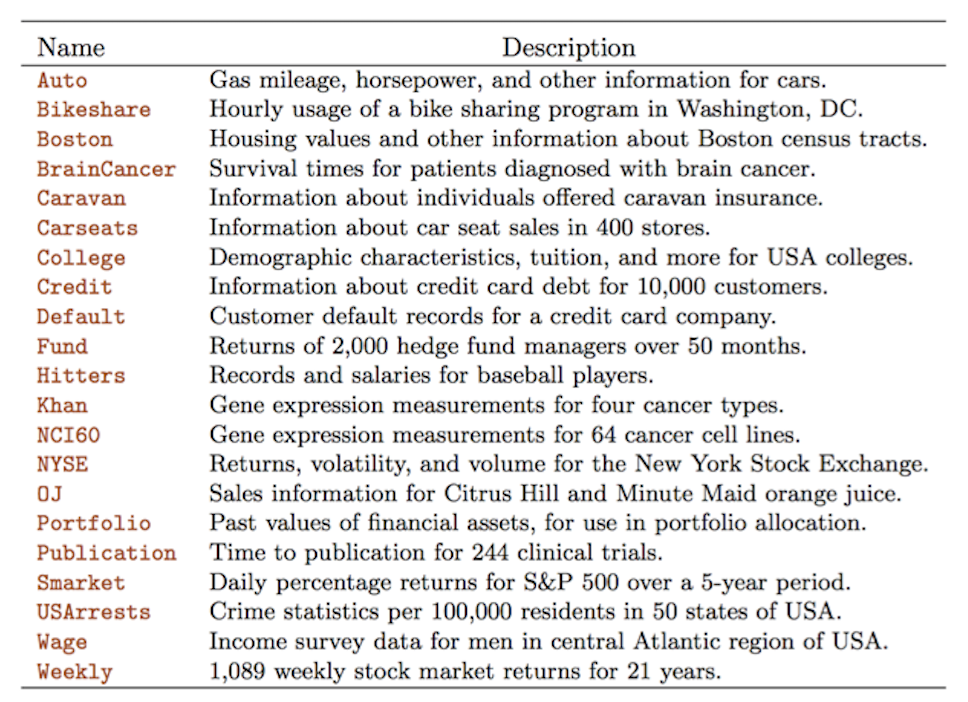
When you run library(ISLR2), these data sets will be
loaded into your current R session. You can use the familiar
? syntax to read the manual for these data sets. For
example, by running ?Wage, the documentation for the
Wage dataset will be opened.
Choose one dataset from the 21 datasets above, perform some exploratory analysis, and then conduct some classification analysis.
You may refer to our course website to see some classification
analyses of the Default dataset and the stock market
dataset.
Colophon. This document is built with Pandoc and Knitr, with the following knitr setup:
knitr::opts_chunk$set(collapse = TRUE, comment = "#>")